Preserving the Web
As Sarah and I were in the middle of moving, packing our lives into cardboard boxes, we unearthed a bunch of old laptops. Before donating them, I cracked them open to back everything up — and found a ton of old websites I’d worked on over the years. Rather than just shuffle the files endlessly between hard drives, I resolved to get them all online.
Enter jake.museum  JAKE.MUSEUM A collection of visual and hypertext media.
JAKE.MUSEUM A collection of visual and hypertext media. jake.museum : an online collection of my web design and development work, from 2007 to the present day.
While this work dates back to my junior year of high school, I started building websites in late middle school, which means that a good three or so years have gone missing. You can still find hints of them in old blog posts alluding to earlier designs, but anything beyond that has been lost.
Today, when most projects start with a git repository, it sounds ridiculous that you could just “lose” a website. But GitHub wasn’t created until I was almost 18, and wouldn’t become commonplace until years later. For my senior project in college 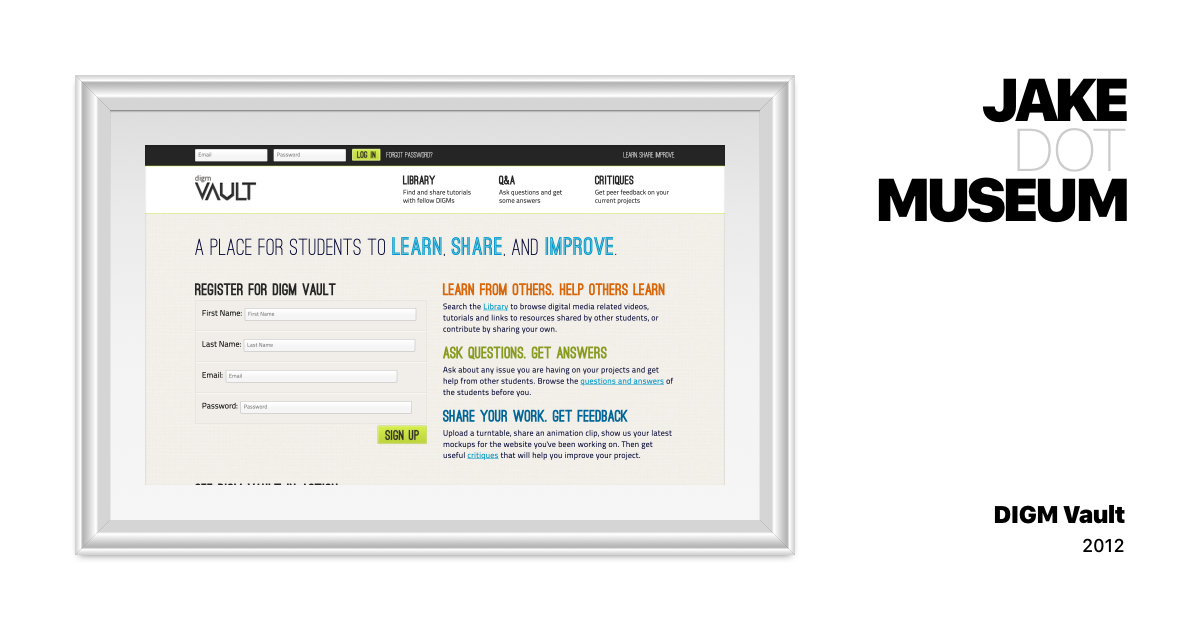 DIGM Vault | JAKE.MUSEUM A collection of visual and hypertext media.
DIGM Vault | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/digmvault/ , we decided to try out this cool thing called version control — with a self-hosted SVN
![]() Apache Subversion - Wikipedia
Apache Subversion - Wikipedia en.wikipedia.org/wiki/Apache_Subversion repo. It was truly a different time.
In spite of that, I seem to have a decent record of sites I’ve worked on for the past decade and a half. But finding the source code was just the beginning. A lot has changed since 2007, and getting these old sites up and running again is not as simple as plopping the files on a webserver.
As with any restoration project, there have been a bunch of bumps in the road. Here’s what I ran into trying to restore all these sites:
Build Systems
For any site that had a compilation step, I had to get the build system working again. Most of these just required an npm install, although in some cases I had to downgrade my Node version or fiddle around with the versions of various dependencies. Today, lock files should mostly mitigate this issue.
Experimental CSS
Ten years ago, many of the CSS properties we now take for granted were locked behind vendor prefixes  Vendor Prefix - MDN Web Docs Glossary: Definitions of Web-related terms | MDN Browser vendors used to add prefixes to experimental or nonstandard CSS properties and JavaScript APIs, so developers could experiment with new ideas. This, in theory, helped to prevent their experiments from being relied upon and then breaking web developers' code during the standardization process.
Vendor Prefix - MDN Web Docs Glossary: Definitions of Web-related terms | MDN Browser vendors used to add prefixes to experimental or nonstandard CSS properties and JavaScript APIs, so developers could experiment with new ideas. This, in theory, helped to prevent their experiments from being relied upon and then breaking web developers' code during the standardization process.  developer.mozilla.org/en-US/docs/Glossary/Vendor_Prefix and didn’t work on all browsers. Ideally, I should have their all browsers’ prefixes and their non-prefixed counterparts as well, but there were a bunch of places in which I forgot. This was easily fixed by filling the gaps with the non-prefixed properties.
developer.mozilla.org/en-US/docs/Glossary/Vendor_Prefix and didn’t work on all browsers. Ideally, I should have their all browsers’ prefixes and their non-prefixed counterparts as well, but there were a bunch of places in which I forgot. This was easily fixed by filling the gaps with the non-prefixed properties.
Slightly more annoying were properties that have changed in the intervening years. When I made Portal 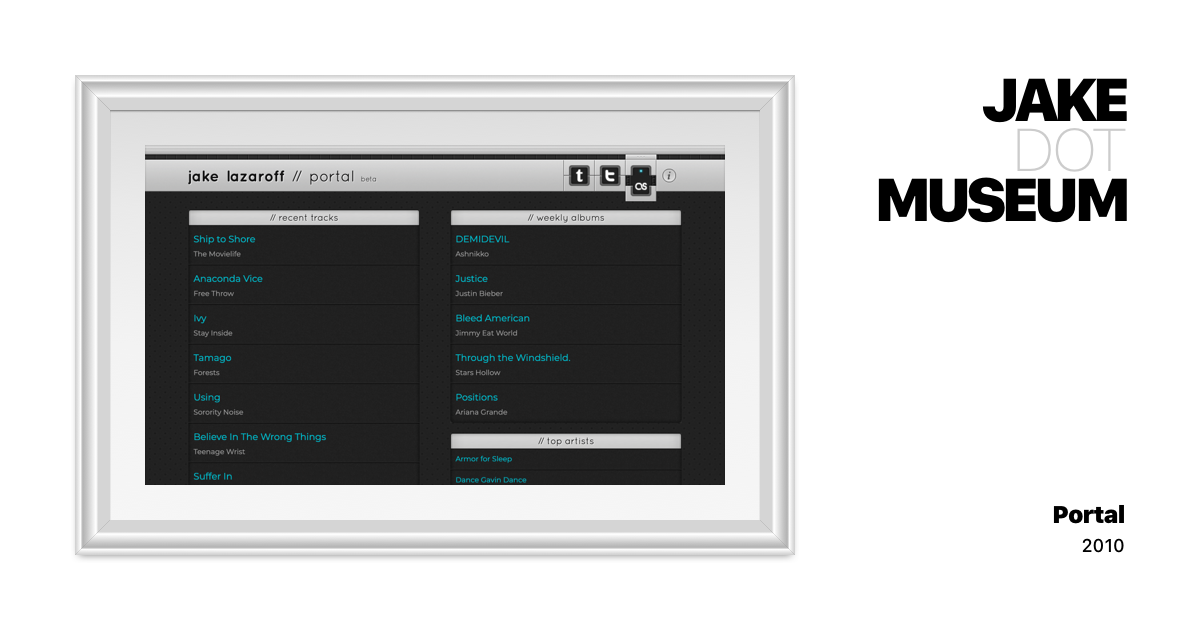 Portal | JAKE.MUSEUM A collection of visual and hypertext media.
Portal | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/portal/ ,
border-image didn’t need to be explicitly told to draw the background in the center. It took a bit more digging through MDN to figure out exactly what the problem was.
Server Side Code
A lot of my early sites used SSI, or Server Side Includes  Apache httpd Tutorial: Introduction to Server Side Includes - Apache HTTP Server Version 2.4
Apache httpd Tutorial: Introduction to Server Side Includes - Apache HTTP Server Version 2.4 
<!--#include virtual="/includes/top.html" -->
When someone requested the page, Apache would replace that comment with the contents of the file at /includes/top.html. I could define all the common markup in a single place, and the server would take care of building the page. Squeaky clean!
That is, until it’s a full decade later and you’re trying to get the site working again. Without Apache there to make the magic happen, SSI are just normal HTML comments — and if you’re using them for significant portions of your webpage, or to link stylesheets or scripts, things can look pretty threadbare. This was easy to solve: I just pretended to be a web server and manually replaced the SSI comments with the included text.
With fully dynamic pages, things started to get sticky. In addition to server configuration, I had to deal with code I wrote a decade or more ago.
My concerts list  Concerts | JAKE.MUSEUM A collection of visual and hypertext media.
Concerts | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/concerts/ , written in PHP, pulled events from a Google calendar. When I tried to bring it back online, the main page returned a 500; it turns out that I wrote some weird routing code that depended on a specific Apache configuration.
The more complicated the dynamic code, the trickier it was to bring back. The second A-Team site  The A-Team v2 | JAKE.MUSEUM A collection of visual and hypertext media.
The A-Team v2 | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/theateam-v2/ was built using a CMS called Perch
 The Really Little Content Management System Perch is a PHP content management system that installs on your own website. Perch is supported and regularly updated, and used by thousands of happy customers around the world.
The Really Little Content Management System Perch is a PHP content management system that installs on your own website. Perch is supported and regularly updated, and used by thousands of happy customers around the world. grabaperch.com/ . I tried running it locally on my current computer, but it won’t run on newer versions of PHP, and I couldn’t figure out how to install an older one. Upgrading the CMS was out of the question; who knows how many breaking changes there have been in the past decade.
By luck, I ended up finding the website working on my old computer. I still haven’t gotten it running on a new system, but at least I got the HTML out. It’s a good thing I embarked on this project before ditching the laptop — it would have been way more difficult to resurrect this from a backup than a running instance.
Once I got any dynamic page working correctly, I would save all the HTML to keep a static version as a baseline. While this worked fine for sites that were view only, interactive ones were a tougher nut to crack. SlideToLock  SlideToLock | JAKE.MUSEUM A collection of visual and hypertext media.
SlideToLock | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/slidetolock/ let you log in and change the theme to resemble iOS or Android, which I’m not sure how to make work with a static version. DIGM Vault
DIGM Vault | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/digmvault/ is even more difficult — the whole thing is a heavily interactive server-side web application. I settled on archiving the marketing pages for now, but I’d love to figure out a way to get the whole thing up and running.
Databases
Although I was able to recover the designs for a lot of the CMS websites eventually, I can’t say the same for the content, which was stored in databases. I’ve tried logging into places where I used to host things — old email accounts, Joyent, NearlyFreeSpeech — but I haven’t found anything at all. The accounts are either gone, or registered with some old email address I’ve forgotten about.
Luckily, some of the local databases on my old computer seem to have a mix of production and development data. I find it mildly surprising that I ported the production data over — maybe I would write posts in development before copying to production, or I needed realistic data to work on the sites? Either way, I’m not looking the gift horse in the mouth.
External Services
The whole point of the web is that pages can connect to each other. But it’s a double-edged sword: pages can change and disappear, and relying on something you don’t control means your website can unexpectedly break.
In some cases, the issue is that APIs have since changed. The original website for The A-Team 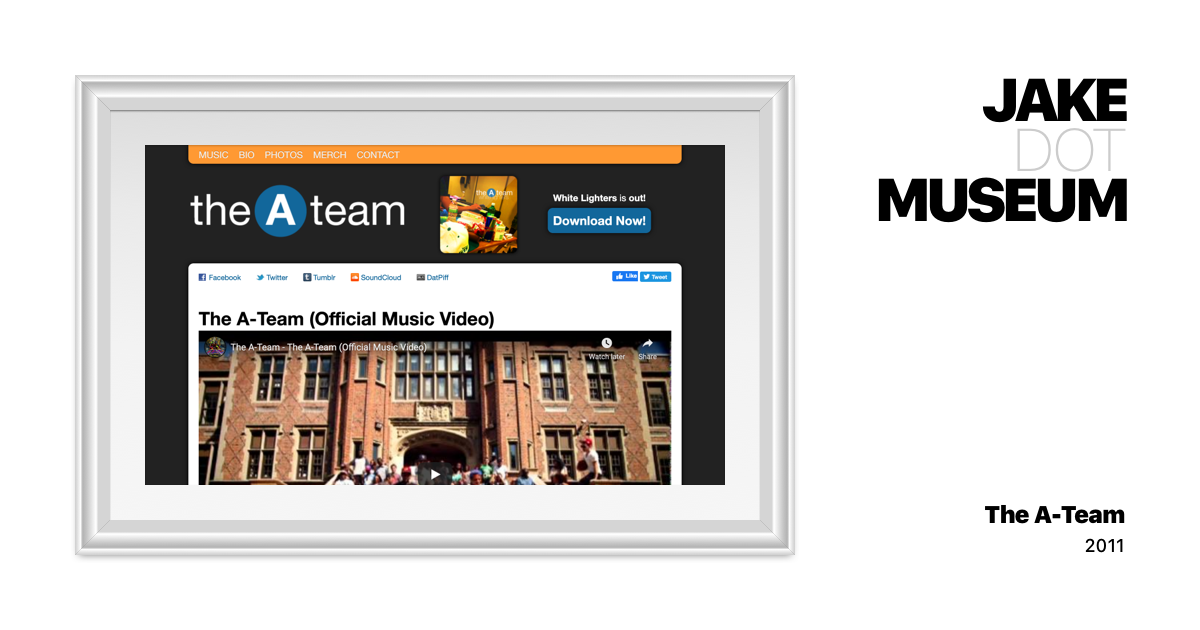 The A-Team v1 | JAKE.MUSEUM A collection of visual and hypertext media.
The A-Team v1 | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/theateam-v1/ has a bunch of SoundCloud embeds. Apparently, the embed codes from that time no longer work; I had to check SoundCloud and replace them with the current version. The embedded player probably doesn’t look exactly like it did in 2011, but it still works for now.
Of course, the embed still relies on SoundCloud’s continued existence and support. To make it really future proof, I’d need to somehow mirror it locally. I haven’t solved this one yet — even if I downloaded all the assets, I’d need to change their code to point to my local versions and not their server.
In other cases, the issue is that I no longer pay for services on which I was relying. A lot of these pages used TypeKit to display custom fonts. This was when @font-face was first introduced, before high-quality free fonts were commonplace.
Unfortunately, there’s not a great solution for this. TypeKit still exists as Adobe Fonts  Adobe Fonts - Wikipedia
Adobe Fonts - Wikipedia en.wikipedia.org/wiki/Adobe_Fonts , but since these websites are up for archival purposes I don’t want to go back to relying on it. To make matters worse, a lot of the fonts I used aren’t free, and I don’t want to pay a lot or break the licenses. I settled for swapping in free approximations of commercial fonts — League Gothic
League Gothic | The League of Moveable Type An open-source, free-to-use, free-to-learn-from typeface designed by Caroline Hadilaksono, Micah Rich & Tyler Finck, open-sourced & published by The League in 2009.
www.theleagueofmoveabletype.com/league-gothic instead of Franklin Gothic URW
 Franklin Gothic URW | Adobe Fonts
Explore Franklin Gothic URW available at Adobe Fonts.
Franklin Gothic URW | Adobe Fonts
Explore Franklin Gothic URW available at Adobe Fonts. fonts.adobe.com/fonts/franklin-gothic-urw , Montserrat
 Montserrat Font Free by Julieta Ulanovsky » Font Squirrel Download and install the Montserrat free font family by Julieta Ulanovsky as well as test-drive and see a complete character set.
Montserrat Font Free by Julieta Ulanovsky » Font Squirrel Download and install the Montserrat free font family by Julieta Ulanovsky as well as test-drive and see a complete character set. www.fontsquirrel.com/fonts/montserrat instead of Proxima Nova
Proxima Nova | Adobe Fonts
Explore Proxima Nova designed by Mark Simonson at Adobe Fonts. fonts.adobe.com/fonts/proxima-nova , etc.
For sites that load dynamic content, the issue is even more dire.
Listen  Listen | JAKE.MUSEUM A collection of visual and hypertext media.
Listen | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/listen/ pulled the liked songs from my SoundCloud account. I grabbed the API response and saved the JSON, then downloaded any audio and image files. This was easier to mirror locally than the aforementioned SoundCloud embeds, since I only had to change my own code as opposed to theirs.
The second A-Team website The A-Team v2 | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/theateam-v2/ cached tweet text locally, but it hotlinked the avatars. Some of the accounts have been renamed or deleted, and others have changed their avatars; those images are never coming back.
The entropy wasn’t limited to third-party services, either. My development copy of SlideToLock SlideToLock | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/slidetolock/ was linking to images on the production site. I’m not sure why I decided to do things that way, but those images are lost as a result.
Flash
I never really worked with Flash outside of school, but there were a couple projects I remember being particularly proud of, like my Vector Authoring I  Vector Authoring I | JAKE.MUSEUM A collection of visual and hypertext media.
Vector Authoring I | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/vectorauthoring-1/ and Vector Authoring II
 Vector Authoring II | JAKE.MUSEUM A collection of visual and hypertext media.
Vector Authoring II | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/vectorauthoring-2/ finals.
Flash Player reached end of life  Adobe Flash Player End of Life Adobe Flash Player End of Life general information
Adobe Flash Player End of Life Adobe Flash Player End of Life general information www.adobe.com/products/flashplayer/end-of-life.html at the end of 2020, and browsers swiftly removed support for it. As such, there’s no longer an easy way to view Flash files on the web. There’s a community effort to build a Flash player emulator called Ruffle Ruffle Ruffle is a Flash Player emulator written in Rust. Ruffle targets both desktop and the web using WebAssembly.
 ruffle.rs/ , which is what I’m using to display the files now. But it’s still a young project missing some important features — most glaringly, support for ActionScript 3.
ruffle.rs/ , which is what I’m using to display the files now. But it’s still a young project missing some important features — most glaringly, support for ActionScript 3.
I’ve tried to use Ruffle to embed my projects, but they were all written using — you guessed it! — ActionScript 3, so they don’t really work. Ruffle displays the graphics fine, but it won’t interpret any of the scripting. Some elements appear clickable, since hover and down states weren’t defined in ActionScript, but for all intents and purposes it’s just a very fancy JPG.
Pending a more mature community replacement, the most reliable approach for playing Flash files is to download the desktop Flash player Adobe Flash Player End of Life Adobe Flash Player End of Life general information www.adobe.com/support/flashplayer/debug_downloads.html (called the “Flash Player projector”).
Archived Copies
When I couldn’t find the files anywhere, or they were missing content, I would try to find any lingering trace of the original websites online.
With Drexel University Replay, I struck a gold mine: the site is actually still up Drexel Game Design replay.drexel.edu/ ! I archived it with
wget, which has a bunch of flags you can use to download websites locally  Make Offline Mirror of a Site using `wget` Sometimes you want to create an offline copy of a site that you can take and view even without internet access. Using wget you can make such copy easily: wget –mirror –convert-links …
Make Offline Mirror of a Site using `wget` Sometimes you want to create an offline copy of a site that you can take and view even without internet access. Using wget you can make such copy easily: wget –mirror –convert-links …  www.guyrutenberg.com/2014/05/02/make-offline-mirror-of-a-site-using-wget/ . If they ever take it down or redesign it, I’ll still have my copy.
www.guyrutenberg.com/2014/05/02/make-offline-mirror-of-a-site-using-wget/ . If they ever take it down or redesign it, I’ll still have my copy.
inciteXchange 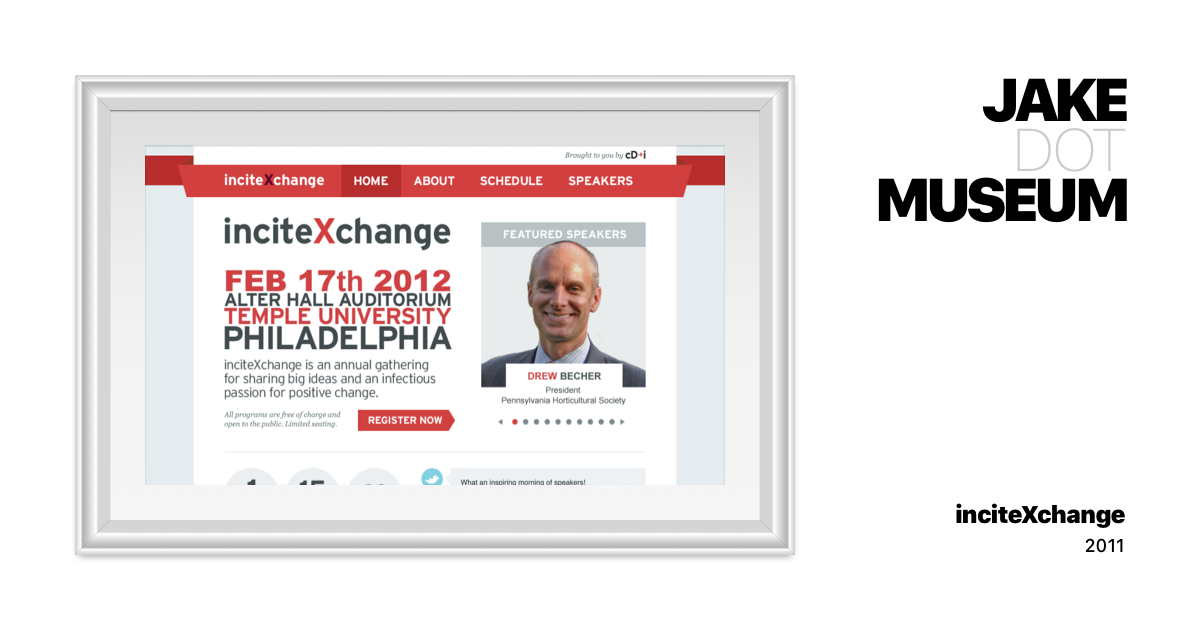 inciteXchange | JAKE.MUSEUM A collection of visual and hypertext media.
inciteXchange | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/incitexchange/ was a site I built during my internship at Electronic Ink. I doubt I ever had the source code on a personal computer, and the site itself is now offline. Fortunately, the Internet Archive preserved a copy, albeit with modifications made after had I left the internship. I downloaded it and painstakingly fixed the markup and asset URLs to make it work locally. The original version I created is unsalvageable, as the Internet Archive didn’t save any of the images — although you can see screenshots in the fourth version of jakelazaroff.com
 jakelazaroff.com v4 | JAKE.MUSEUM A collection of visual and hypertext media.
jakelazaroff.com v4 | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/jakelazaroff-v4/ .
For Hexnut v4  Hexnut v4 | JAKE.MUSEUM A collection of visual and hypertext media.
Hexnut v4 | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/hexnut-v4/ and blog.jakelazaroff.com
 blog.jakelazaroff.com | JAKE.MUSEUM A collection of visual and hypertext media.
blog.jakelazaroff.com | JAKE.MUSEUM A collection of visual and hypertext media. jake.museum/jakelazaroff-blog , the problem was a little different: I had the templates and styles for the sites, but the content had gone missing. In both cases, the Internet Archive came through. It had saved markup with no styles or images — the exact missing puzzle piece I needed. From there, I combined the two to get the websites functional again.
This tactic was more effective for websites I built for clients than for myself, presumably because my own sites weren’t popular enough to warrant much archival effort. And even when I was able to find archived copies, pages would often be missing, so it’s still not a complete record.
The Internet Archive actually has copies of my very first sites — mlingojones.com  Wayback Machine
Wayback Machine 
 web.archive.org/web/20091226003223/http://jakelazaroff.com/ — but sadly, the CSS files 404, so you can’t see the designs.
web.archive.org/web/20091226003223/http://jakelazaroff.com/ — but sadly, the CSS files 404, so you can’t see the designs.
There are a few lessons here.
An obvious one: use source control. This isn’t nearly as much of a problem these days, since these services are ubiquitous. (Use LFS Git Large File Storage (LFS) | GitLab Documentation for GitLab Community Edition, GitLab Enterprise Edition, Omnibus GitLab, and GitLab Runner. docs.gitlab.com/ee/topics/git/lfs/ if you have a lot of media files, like I do).
Don’t use nonstandard technologies like Flash. This was pretty clear at the time, too, which is why I didn’t make a lot of stuff with it. I’m hoping the Ruffle developers keep up their great work, but I can’t say for sure that my Flash projects will ever be fully viewable on the web again.
Store as many dependencies as you can alongside your source code. That means keeping any server configuration, so you can recreate it later. It means embedding assets such as fonts directly, rather than using a third-party service.
Test your websites every so often, and fix any bugs incrementally. One reason older PHP sites so were difficult to recover was that there have been three major PHP releases since then. The only thing more daunting than updating code you haven’t touched since 2011 is recreating a decade-old development environment.
This is probably a hot take, but don’t use a database. I have a lot of respect for WordPress and the various CMS communities out there, but I would probably still have a lot of these old blog posts had I stored them with the website source code. At the very least, back up the database and save it somewhere you’re likely to keep.
That goes double for any site powered by a CMS API, which is popular these days because of the Jamstack trend. If the API changes, you’re in for a rough time getting things working again. In the absolute worst case, you’ll be unable to access your account for some reason, and your content will be gone forever.
Most effectively: save static versions of your websites while you still have them! You have a working development environment and database and all your subscriptions right now. It will only ever get harder to preserve the sites you spent hours sweating over.
Finally, consider donating to the Internet Archive Internet Archive: Digital Library of Free & Borrowable Books, Movies, Music & Wayback Machine archive.org/donate/ . They helped me rescue sites for which I had lost either the source or the content which otherwise would have been gone forever.
If you take one thing away from this post, let it be this: please keep your old websites! Back them up, restore them, put them online and make your own museum! The web — for better and for worse — is one of our most amazing inventions, specifically because it’s so participatory. But it’s also extremely fragile, and it only takes a few years for dormant websites to start rotting away.
You, me, our coworkers and friends and family — we’re all part of this grand experiment, whether we learned HTML on Funky Chickens, PHP on Stack Overflow or JavaScript on Glitch. Even if all we do is just post on Tumblr! The things we’re creating are part of history. The web is precious, and it’s worth preserving.